
بقلم الدكتور المهندس محمد ملحم*
تمهيد
يعد الذكاء الاصطناعي التوليدي أكثر أشكال الذكاء الاصطناعي رواجاً اليوم، وهو الذي يمكّن روبوتات الدردشة مثل ChatGPT وErnie وLLaMA وClaude وCommand من القيام بعملها. بالإضافة إلى مولدات الصور مثل DALL-E 2 وStable Diffusion وAdobe Firefly وMidjourney. الذكاء الاصطناعي التوليدي هو فرع من الذكاء الاصطناعي يمكّن الآلات من تعلم الأنماط من مجموعات بيانات ضخمة ومن ثم إنتاج محتوى جديد بشكل مستقل بناءً على تلك الأنماط.
على الرغم من أن الذكاء الاصطناعي التوليدي جديد إلى حد ما، إلا أنه يوجد العديد من الأمثلة على النماذج التي يمكنها إنتاج النصوص والصور ومقاطع الفيديو والأصوات والنماذج ثلاثية الأبعاد.
تم تدريب العديد من “النماذج الأساسية” على ما يكفي من البيانات لتكون مؤهلة للقيام بمجموعة واسعة من المهام. على سبيل المثال، يمكن لنموذج اللغة الكبير LLM إنشاء مقالات ورموز حاسوبية ووصفات وهياكل بروتينية ونكات ونصائح طبية تشخيصية وغير ذلك الكثير. ويمكنه أيضاً من الناحية النظرية إنشاء تعليمات لبناء قنبلة أو إنتاج سلاح بيولوجي، على الرغم من وجود ضمانات تمنع مثل هذه الأنواع من سوء الاستخدام.
الفرق بين الذكاء الاصطناعي والتعلم الآلي والذكاء الاصطناعي التوليدي
يشير (الذكاء الاصطناعي AI) إلى مجموعة واسعة من الأساليب الحسابية لمحاكاة الذكاء البشري. (التعلم الآلي ML) هو مجموعة فرعية من الذكاء الاصطناعي؛ فهو يركز على الخوارزميات التي تُمكن الأنظمة من التعلم من البيانات وتحسين أدائها. قبل ظهور الذكاء الاصطناعي التوليدي، تتعلم معظم نماذج تعلم الآلة من مجموعات البيانات لأداء مهام مثل التصنيف أو التنبؤ. الذكاء الاصطناعي التوليدي هو نوع متخصص من التعلم الآلي يتضمن نماذج تؤدي مهمة إنشاء محتوى جديد والدخول في عالم الإبداع.
بُنى نماذج الذكاء الاصطناعي التوليدي
يتم إنشاء النماذج التوليدية باستخدام مجموعة متنوعة من بُنى الشبكات العصبية، وبحسب تصميم وبنية النموذج يتحدد كيفية تدفق المعلومات من خلاله. بعض البنى الأكثر شهرة هي أجهزة التشفير التلقائي المتغيرة (VAEs) Variational Autoencoders ، وشبكات الخصومة التوليدية (GANs) Generative Adversarial Networks، وبنى التعلم العميق مثل المحولاتTransformer التي تم عرضها لأول مرة في ورقة بحثية مبتكرة عام 2017 من Google. تعمل المحولات على تشغيل نماذج اللغات الكبيرة LLM ولكنها أقل ملاءمة للأنواع الأخرى من الذكاء الاصطناعي التوليدي مثل توليد الصور والصوت.
تقوم أجهزة التشفير بضغط البيانات المدخلة في مساحة ذات أبعاد أقل، تُعرف باسم المساحة الكامنة (أو المُضمّنة)، والتي تحافظ على البيانات الأكثر أهمية. يمكن لجهاز فك التشفير بعد ذلك استخدام هذا التمثيل المضغوط لإعادة بناء البيانات الأصلية. بمجرد تدريب جهاز التشفير التلقائي بهذه الطريقة، يمكنه استخدام مدخلات جديدة لتوليد ما يعتبره المخرجات المناسبة. غالباً ما يتم نشر هذه النماذج في أدوات توليد الصور، وقد وجدت أيضاً استخداماً في اكتشاف الأدوية، حيث يمكن استخدامها لإنشاء جزيئات جديدة ذات خصائص مرغوبة.
يتطلّب التدريب في شبكات الخصومة التوليدية (GANs) خصمين هما المولد generator والمُميّز discriminator . يسعى المولد إلى إنشاء بيانات واقعية، بينما يهدف المميّز إلى التمييز بين المخرجات المولدة والمخرجات الحقيقية. في كل مرة يلتقط فيها المُميِّز مخرجاً مُولداً يستخدم المولد التغذية الراجعة لمحاولة تحسين جودة مخرجاته، وفي الوقت نفسه يتلقى المُميِّز أيضاً تغذية راجعة حول أدائه. يؤدي هذا التفاعل العدائي إلى تحسين كلا المكونين، مما يؤدي إلى إنشاء محتوى يبدو أصيلاً بشكل متزايد.
أما بالنسبة للمحولات كأحد بنى الذكاء الاصطناعي التوليدي فتكمن قوتها في آلية التنبيه Attention Mechanism (AM) الخاصة بها، والتي تمكّن النموذج من التركيز على أجزاء مختلفة من تسلسل الإدخال أثناء إجراء التنبؤات. في النماذج اللغوية، يتنبأ المحول بالكلمة التالية في سلاسل الكلمات المُشكّلة للجمل. يمكن للمحولات معالجة جميع عناصر التسلسل على التوازي، وهذا التوازي يجعل التدريب أسرع وأكثر كفاءةً. عندما أضاف المطوّرون مجموعاتٍ كبيرة ًمن البيانات النصية لنماذج المحولات للتعلم منها، ظهرت روبوتات الدردشة الرائعة اليوم.
تطوير نماذج الذكاء الاصطناعي التوليدي
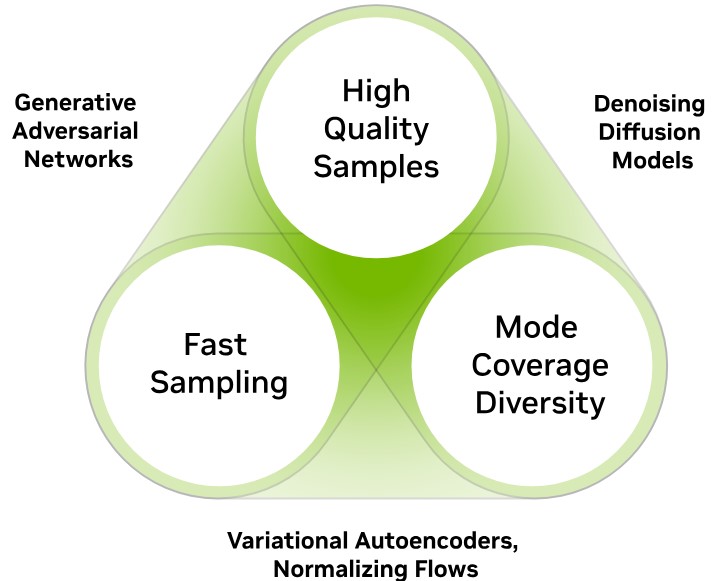
المتطلبات الرئيسية الثلاثة لنموذج الذكاء الاصطناعي التوليدي الناجح هي:
–الجودة Quality، إذ يُعد الحصول على عينات خرج بجودة عالية أمراً بالغ الأهمية،
–التنوع Diversity، هو القدرة على التقاط التفاصيل الصغيرة في البيانات دون التضحية بالجودة،
–السرعة Speed، هي ميزة مهمة جداً في التطبيقات التفاعلية (انظر الشكل(1)).
-نماذج الانتشار Diffusion models: تُعرف أيضاً باسم النماذج الاحتمالية للانتشار لتقليل الضوضاء Denoising Diffusion Probabilistic Models (DDPMs)، ونماذج الانتشار هي نماذج توليدية تحدد متجهات الميزات بخطوتين أثناء التدريب: الأولى الانتشار الأمامي وتضيف ببطء ضوضاء عشوائية إلى بيانات التدريب، والثانية الانتشار العكسي وتعمل على عكس الضوضاء لإعادة بناء عينات البيانات. يمكن إنشاء بيانات جديدة عن طريق تشغيل عملية تقليل الضوضاء العكسية بدءاً من الضوضاء العشوائية تماماً.
-أجهزة التشفير التلقائي المتغيرة Variational autoencoders (VAEs): تتكون أجهزة التشفير التلقائي المتغيرة من شبكتين عصبيتين يُشار إليهما عادةً باسم وحدة التشفير ووحدة فك التشفير. يقوم برنامج التشفير بتحويل المدخلات إلى تمثيل أصغر وأكثر كثافة للبيانات. يحافظ هذا التمثيل المضغوط على المعلومات المطلوبة لجهاز فك التشفير لإعادة بناء بيانات الإدخال الأصلي مع تجاهل أي معلومات غير ذات صلة. تعمل وحدتا التشفير وفك التشفير معاً لتمثيل فعال وبسيط للبيانات الكامنة.
شبكات الخصومة التوليدية (GANs): وقد تمّ اكتشاف شبكات الخصومة التوليدية في عام 2014، وكانت تعتبر المنهجية الأكثر استخداماً بين الشبكات الثلاث قبل النجاح الأخير لنماذج الانتشار. وكما تمت الإشارة سابقاً: المولد يولد محتوى جديد والمُميّز يتعلم تمييز المحتوى الجديد فيما إذا كان حقيقياً أو مزيفاً.
-تساعد شبكة المحول كواحدة من أكثر الشبكات استخداماً في تطوير النماذج التوليدية. فهي على غرار الشبكات العصبية التكرارية، صُممت لمعالجة بيانات الإدخال المتسلسلة بشكل متوازٍ. توجد آليتان تجعلان المحولات بارعةً بشكل خاص في تطبيقات الذكاء الاصطناعي التوليدية القائمة على النصوص: التنبيه الذاتي self-attention والتشفير الموضعي positional encodings. تساعد هاتان التقنيتان في تمثيل الزمن وتسمح للخوارزمية بالتركيز على كيفية ارتباط الكلمات بعضها ببعض ولمسافات طويلة. تقوم طبقة التنبيه الذاتي بتعيين وزن لكل جزء من المدخلات. يشير الوزن إلى أهمية هذا المدخل في سياق بقية المدخلات. التشفير الموضعي هو تمثيل لترتيب ورود كلمات الإدخال.
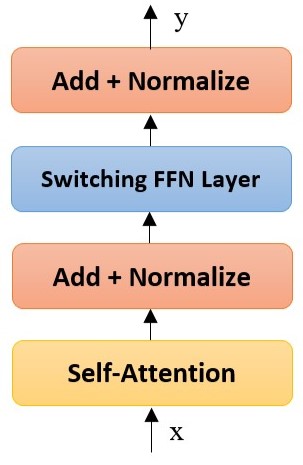
يتكون المحول من عدة طبقات وكل طبقة محول مستقل. على سبيل المثال، يحتوي المحول على طبقات تنبيه ذاتي self-attention، وطبقات تغذية أمامية، وطبقات تسوية normalization (انظر الشكل (2))، تعمل جميعها معاً لفك تشفير تدفقات البيانات المميزة والتنبؤ بها، والتي يمكن أن تتضمن نصاً أو تسلسلاتٍ بروتينية أو حتى دفقات من الصور.
كيف تعمل نماذج اللغات الكبيرة LLM؟
يعتمد تدريب LLM على المحولات من خلال إعطاء المحول مجموعة بيانات واسعة من النصوص. تلعب آلية التنبيه AM دوراً مهماً في معالجة الجمل والبحث عن الأنماط من خلال النظر إلى جميع الكلمات في الجملة مرة واحدة، ومن ثم يبدأ تدريجياً بفهم الكلمات التي ترد معاً عادةً وأيها الأكثر أهمية لمعنى الجملة. يتعلم المحول هذه الأشياء من خلال محاولة التنبؤ بالكلمة التالية في الجملة ومقارنتها بالحقيقة. تعمل أخطاؤه كإشارات ردود فعل تدفع النموذج لإعادة ضبط أوزان الكلمات قبل المحاولة مرة أخرى.
عملية التدريب بمصطلحات أكثر تقنية تتم بتقسيم النص الموجود في بيانات التدريب إلى عناصر تسمى الرموز المميزة، وهي عبارة عن كلمات أو أجزاء من الكلمات – ولكن من أجل التبسيط، نقول إن جميع الرموز المميزة هي كلمات. أثناء قيام النموذج بمراجعة الجمل الموجودة في بيانات التدريب يُعرّف العلاقات بين الرموز المميزة ويُنشئ متّجَهة من الأرقام. تمثل الأرقام الموجودة في المتّجَه السمات المختلفة للكلمة: معانيها الدلالية، وعلاقتها بالكلمات الأخرى، وتكرار استخدامها وما إلى ذلك. سيكون للكلمات المتشابهة مثل أنيق وفخم (elegant and fancy) مُتجَهاتٌ بأبعادَ متساويةٍ تقريباً وميزات متشابهة. تتضمن المتّجَهات الأوزان (بارامترات LLM) المرتبطة بجميع الكلمات وآلية التنبيه، ويُعتبر GPT-4 وOpenAI النموذج الأكثر تفوقاً في الوقت الحالي ويحتوي على أكثر من تريليون بارامتر (انظر الشكل (3)).
مع توفر ما يكفي من البيانات والزمن للتدريب، يبدأ النموذج LLM في فهم تعقيدات اللغة من خلال النظر إلى النص جملة فجملة. وفي هذه الأثناء تلتقط آلية التنبيه العلاقات بين الكلمات عبر تسلسل نصي أطول يتكون من العديد من الفقرات. بعد الانتهاء من تدريب LLM ويصبح جاهزاً للاستخدام تبقى آلية التنبيه قيد العمل عندما يقوم النموذج بإنشاء نص استجابة لمطالبة ما. عند إنشاء أجزاء أطول من النص يتنبأ النموذج بالكلمة التالية في سياق جميع الكلمات التي كتبها حتى الآن؛ وهذه الوظيفة تزيد من تماسك واستمرارية كتابتها.

الهلوسة في النماذج اللغوية الكبيرة
ربما تكون قد سمعت في بعض الأحيان عن الهلوسة hallucinate في نماذج LLM، وهي طريقة مهذبة للقول إنهم يختلقون الأشياء بشكل مقنع للغاية. يقوم النموذج أحياناً بإنشاء نص يناسب السياق ويكون صحيحاً نحوياً ولكن المضمون خاطئ وليس له معنى Invalid . تنبع هذه العادة السيئة من تدريب النماذج LMMs على كميات هائلة من البيانات المستمدة من الإنترنت والكثير منها ليس دقيقاً في الواقع. وبما أن النموذج يحاول ببساطة التنبؤ بالكلمة التالية في تسلسل ما بناءً على ما رآه فينتج نصاً معقولاً ولكن ليس له أساس في الواقع.
جدلية الذكاء الاصطناعي التوليدي
أحد مصادر الجدل حول الذكاء الاصطناعي التوليدي هو مصدر بيانات التدريب الخاصة به. معظم شركات الذكاء الاصطناعي التي تدرّب نماذج كبيرة لإنشاء النصوص والصور والفيديوهات والأصوات لم تكن شفافة بشأن محتوى مجموعات بيانات التدريب الخاصة بها. كشفت العديد من التسريبات والتجارب أن مجموعات البيانات هذه تتضمن مواداً محميةً بحقوق الطبع والنشر مثل الكتب والمقالات الصحفية والأفلام. هناك عدد من الدعاوى القضائية الجارية لتحديد ما إذا كان استخدام المواد المحمية بحقوق الطبع والنشر لتدريب أنظمة الذكاء الاصطناعي أمراً عادلاً أم لا، وهل على شركات الذكاء الاصطناعي أن تدفع لأصحاب حقوق الطبع والنشر مقابل استخدام موادهم؟
ومن ناحية أخرى، يشعر الكثير من الناس بالقلق من أن الاستخدام الواسع النطاق للذكاء الاصطناعي التوليدي سيؤثر سلباً على الأشخاص المبدعين الذين يصنعون الفن والموسيقى والأعمال المكتوبة وسيسلبهم وظائفهم. وتسلل القلق أيضاً إلى أصحاب الوظائف الإدارية والمترجمين والقانونيين والصحفيين بسبب بعض عمليات التسريح -المثيرة للقلق – للعمال. ولكن من الصعب القول حتى الآن ما إذا كان الذكاء الاصطناعي التوليدي سيكون موثوقاً بما يكفي لتطبيقات المؤسسات واسعة النطاق بسبب ظاهرة الهلوسة.
وأخيراً، هناك خطر استخدام الذكاء الاصطناعي التوليدي في صنع أشياء سيئة، إذ يمكن استخدام الذكاء الاصطناعي التوليدي في عمليات الاحتيال الشخصية: على سبيل المثال “استنساخ الصوت”، إذ يمكن للمحتالين نسخ صوت شخص معين والاتصال بأسرته لطلب المساعدة (والمال). ويمكن استخدام الذكاء الاصطناعي التوليدي لتوليد معلومات مضللة من خلال إنشاء تمثيلات تبدو معقولة لأشياء لم تحدث أبداً وهو أمرٌ مثيرٌ للقلق عندما يتعلق الأمر بالشأن العام والانتخابات. ويمكن استخدام أدوات توليد الصور والفيديو لإنتاج مواد إباحية. ويمكن لروبوتات الدردشة توجيه الإرهاب نظرياً على الرغم من أن شركات LLM الكبيرة لديها ضمانات لمنع سوء الاستخدام هذا، إلا أن بعض المتسللين يتحايلون على تلك الضمانات، بالإضافة إلى وجود إصدارات LLM مفتوحة المصدر وغير خاضعة للرقابة. بالرغم من هذه السلبيات المحتملة، يمكن للذكاء الاصطناعي التوليدي أن يجعل الناس أكثر إنتاجية ويمكن استخدامه كأداة لتطوير أشكال جديدة من الإبداع.
تطبيقات الذكاء الاصطناعي التوليدي
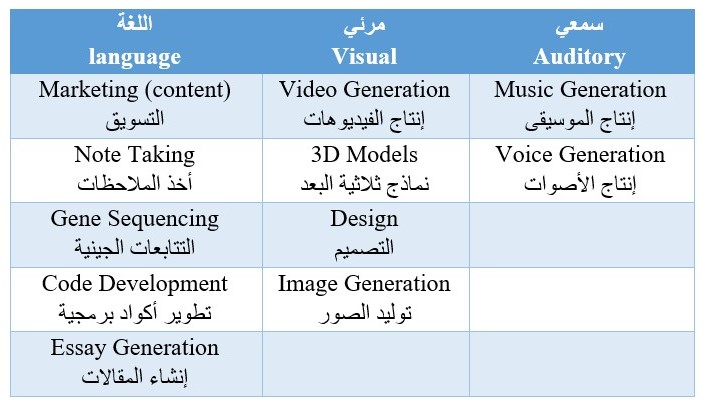
يعد الذكاء الاصطناعي التوليدي أداة قوية بيد المبدعين والمهندسين والباحثين والعلماء وغيرهم إذ يبين الشكل (4) بعض استخداماته. وظهرت في الآونة الأخيرة بعض الأبحاث تستخدم الذكاء الاصطناعي في البحث العلمي.
تحديات الذكاء الاصطناعي التوليدي
لا تزال النماذج التوليدية في مراحلها الأولى، مما يمنحها مساحة واسعة للنمو في المجالات الآتية:
-حجم البنية التحتية للحوسبة Scale of compute infrastructure: تحتاج نماذج الذكاء الاصطناعي التوليدية مليارات البارامترات للتدريب فهي بحاجة إلى خطوط بيانات سريعة وفعالة لتحقيق ذلك. على سبيل المثال، قد تتطلب نماذج الانتشار ملايين أو مليارات الصور لتدريبها. علاوة على ذلك، لتدريب مجموعات البيانات الضخمة هذه توجد حاجة إلى قوة حسابية هائلة ومئات وحدات معالجة الرسومات GPUs.
-سرعة أخذ العينات Sampling speed: نظراً لحجم النماذج التوليدية وتزايد شعبيتها بسبب ما تقدمه من عينات عالية الجودة، أصبحت سرعات أخذ العينات بطيئة وهذا يبدو واضحاً في التطبيقات التفاعلية مثل برامج الدردشة وخدمة الزبائن وغيرها.
-الافتقار إلى بيانات عالية الجودة Lack of high-quality data: بالرغم من وجود مجموعات كبيرة من البيانات على مستوى العالم ولكن لا يمكن استخدام جميع البيانات لتدريب نماذج الذكاء الاصطناعي. ففي كثير من الأحيان يتم استخدام نماذج الذكاء الاصطناعي التوليدي لإنتاج بيانات تركيبية لحالات استخدام مختلفة. على سبيل المثال يوجد عدد قليل من الأصول ثلاثية الأبعاد وتطويرها سيكون مكلفاً ويتطلب مواردَ كبيرةً.
-تراخيص البيانات Data licenses: تزيد التراخيص من تفاقم مشكلة نقص البيانات عالية الجودة، إنّ العديد من المنظمات تكافح من أجل الحصول على ترخيص تجاري لاستخدام مجموعات البيانات الحالية أو لبناء مجموعات بيانات مخصصة لتدريب النماذج التوليدية وهذه عملية مهمة للغاية ومفتاح لتجنب مشكلات انتهاك الملكية الفكرية.
فوائد الذكاء الاصطناعي التوليدي
-يساعد في إنشاء محتوىً جديد وأصلي، مثل الصور ومقاطع الفيديو والنصوص، والتي لا يمكن تمييزها عن المحتوى الذي أنشأه البشر.
-تحسين كفاءة ودقة أنظمة الذكاء الاصطناعي الحالية، مثل معالجة اللغة الطبيعية والرؤية الحاسوبية.
-استكشاف وتحليل البيانات المعقّدة بطرق جديدة.
-يساعد في أتمتة وتسريع مجموعة متنوعة من المهام والعمليات.
الجانب المظلم للذكاء الاصطناعي التوليدي.. سيكون موضوع مقالتنا القادمة!
References
1-Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
2-https://developers.google.com/machine-learning/gan/generator
3-https://blogs.nvidia.com/blog/what-is-a-transformer-model/
4-Huang, Lei, et al. “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.” arXiv preprint arXiv:2311.05232 (2023).
ـــــــــــــــــــــــــــــــــــــــــــــــــــــ
*الدكتور محمد ملحم – أستاذ مساعد في جامعة العين العراقية – كلية التقنيات الهندسية
جميع الآراء الواردة في هذه المقالة لا تعبّر بالضرورة عن رأي مركز جي إس إم وإنما تعبّر عن رأي صاحبها حصراً